Compilers
Ch1
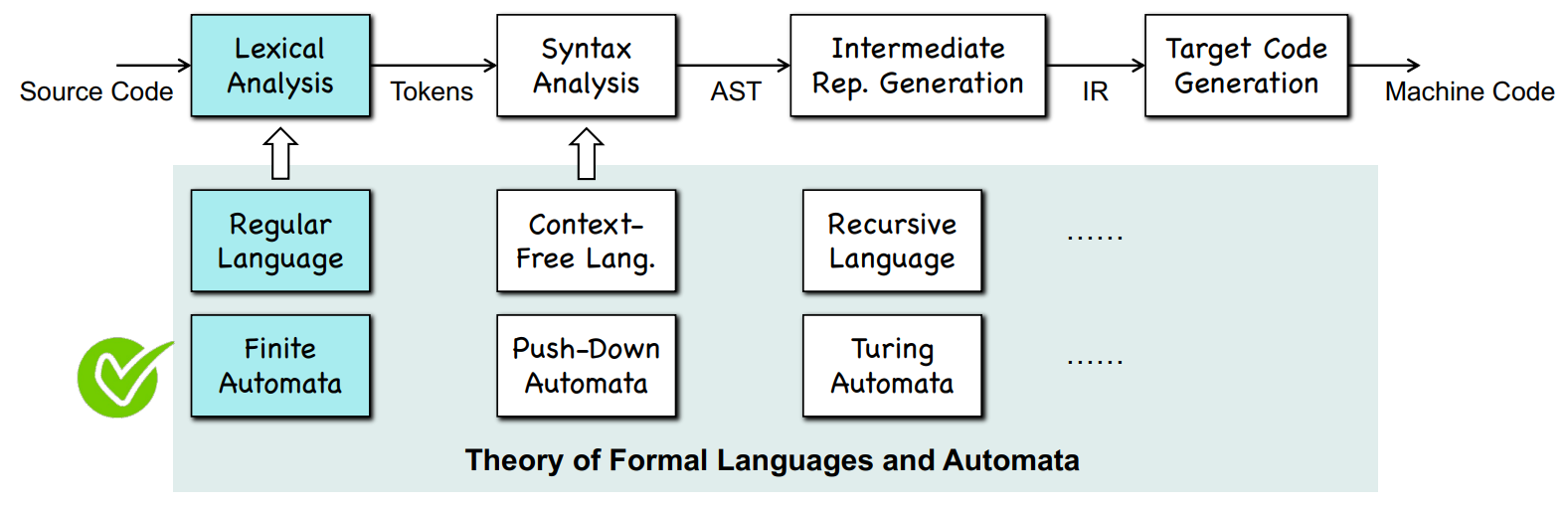
Front End
Lexical Analysis -> Syntax Analysis -> Semantic Analysis
Lexical Analysis (词法分析)
Create tokens
<token-class, attribute>
Syntax Analysis (语法分析)
- Create the abstract syntax tree (AST)
Semantic Analysis (语义分析)
- Check the correct meaning
- Decorate the AST
IR Generation:
- Generate machine-independent intermediate representation (IR) based on the syntax tree
Middle End
Optimizations
Back End
Instruction Selection
- Translate IR to machine code
- Perform machine-development optimization
Register Allocation
Instruction Scheduling
- (for example: parallelism)
Ch3
Ch3-1 Finite Automata
Empty String: ϵ
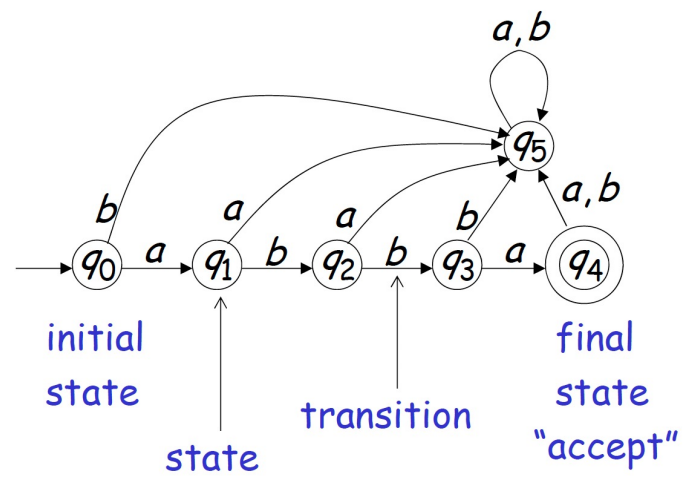
Deterministic Finite Automata
A DFA is formally defined as a 5-tuple (Q, Σ, δ, q₀, F), where:
- Q: A finite set of states.
- Σ: A finite input alphabet.
- δ: A transition function δ: Q × Σ → Q that maps a state and an input symbol to a single next state.
- q₀: The start state, where the DFA begins processing.
- F: A set of accept states, F ⊆ Q.
DFA Minimization
DFA Bi-Simulation
Non-deterministic Finite Autometa
Allow ϵ-transitions.
ϵ-Closure
ϵ-closure(q) returns all states q can reach via ϵ-transitions, including q itself.
From NFA to DFA
ϵ-Closure
- When converting an NFA to a DFA, there is no guarantee that we will have a smaller DFA.
Ch3-2 Lexical Analysis
Laws of Regex
- Commutativity and Associativity
- Identities and Annihilators
- Distributive and Idempotent Law
- Closure
Regex = Regular Language
- Any regex represents a
regular languageNFA/DFA - Any
regular languageDFA can be expressed by a regex
Lexical Analysis
symbol table
Pumping Lemma
If L is an infinite regular language (the set L is infinite),
there must exist an integer m,
for any string w ∈ L with length |w| ≥ m,
we can write w = xyz with |xy| ≤ m and |y| ≥ 1,
such that wi = xyiz ∈ L
Ch4-1
Context-Free Language
Context Free Grammar (CFG)
A context-free grammar is a tuple G = (V, T, S, P)
- V: a finite set of non-terminals
- T: a finite set of terminals, such that V ∩ T = ∅
- S ∈ V: start non-terminals
Regular language ⊆ Context-free language
Context-free language = Push-down automata
Left-Most Derivation (=>lm)
In every step derivation, we replace the left-most non-terminal.
Right-Most Derivation (=>rm)
In every step derivation, we replace the right-most non-terminal.
Parse/Syntax Trees
Parse tree
- Every leaf is a terminal
- Every non-leaf node is a non-terminal
Ambiguity
A grammar is ambiguous if there is a string has two different derivation trees.
Eliminating Ambiguity
Lifting operators with higher priority
Using Ambiguous Grammar
Push-Down Automata (PDA)
NPDA
Context-free language = PDA = NFA + Stack = NPDA (Non-Deterministic PDA)
NPDA/PDA is defined by the septuple:
- Q = (Q, Σ, Γ, δ, q0, z0, F)
- Q: a finite set of states
- Σ: finite input alphabet
- Γ: finite stack alphabet
- δ: Q × (Σ ∪ {ϵ})×Γ ⟼ 2Q× Γ*: transition
- q0 ∈ Q: initial state
- z0 ∈ Γ: stack start symbol
- F ⊆ Q: set of final states
Instantaneous Description
An instantaneous description of a PDA is a triple
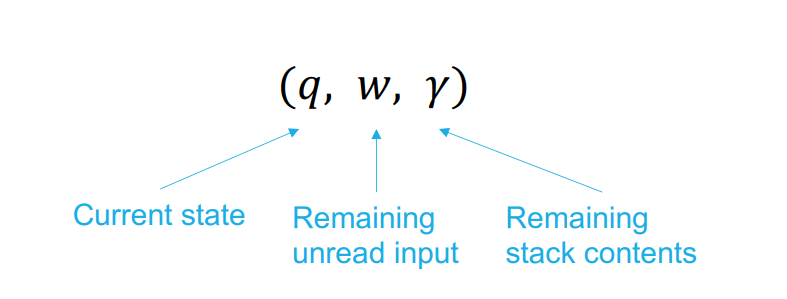
Language of PDA
At the end of computation, we don’t care about stack contents
acceptance by final states:
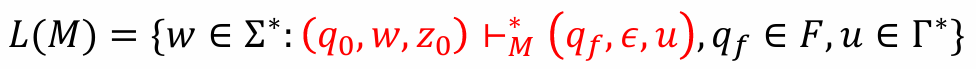
acceptance by empty stack:

Equivalence of PDA and CFG
TBD
Properties of CFL
Closure Properties
Given two CFL, L1 and L2, the following are CFL
- L1 ∪ L2
- L1L2
- L1*
- L1R( = \(\{w^R:w \in L_1 \}\))
Given two CFL, L1 and L2, the following may not be CFL
- L1 ∩ L2( = \(\overline{\overline{L_1} \cup \overline{L_2} }\))
- \(\overline{\textit{L}}\)1
- L1 - L2
Pumping Lemma for CFL
Chomsky Normal Form
\(A \rightarrow BC;\)
\(A \rightarrow \alpha;\)
\(S\rightarrow\epsilon;\)
Pumping Lemma for CFL
Given a CFL \(L\), there exists a constant \(n\) such that we have \(z=uvwxy \in L,\ |z| \geq n\) satisfying the condition below
- \(vx\neq\epsilon\)
- \(|vwx|\leq n\)
- \(\forall i \geq 0,\ z_i=uv^iwx^iy\in L\)
Ch4-2
Top-Down Parsing
Constructing a parse tree in preorder.
- Backtracking may be necessary.
- A left-recursive grammar can cause infinite loops.
Eliminating Left-Recursion
\(A\rightarrow A\alpha\ |\ \beta\) can be transformed into:
\(A\rightarrow \beta A^{'}\)
\(A^{'}\rightarrow\alpha A^{'}\ | \ \epsilon\)
Predictive Parsing
Predictive parsers are recursive descent parser without backtracking.
LL(1)
- L: scanning input from left to right
- L: leftmost derivation
- 1: Using one input symbol of lookahead at each step
FIRST()
\(FIRST(\alpha)\): A set of terminals that 𝛼 may start with.
If \(X\) is a terinal, FIRST(\(X\)) ={\(X\)}
If \(X\rightarrow \epsilon\) is a production, \(\epsilon \in\) FIRST(\(X\))
If \(X \rightarrow Y_1Y_2...Y_k,\)
\(\epsilon \in \cap_{j=1}^{i-1}FIRST(Y_j) \land a \in FIRST(Y_i) \Rightarrow a \in FIRST(X)\)
\(\epsilon \in \cap_{j=1}^{i-1}FIRST(Y_j) \Rightarrow \epsilon \in FIRST(X)\)
FOLLOW()
\(FOLLOW(\alpha)\): A set of terminals that can appear immediately to the right of \(\alpha\)
- \(\$ \in FOLLOW(S)\), where \(\$\) is string's end marker, \(S\) the start non-terminal
- \(A \rightarrow \alpha B\beta \Rightarrow FIRST(\beta)\backslash\{\epsilon\} \subseteq FOLLOW(B)\)
- \(A\rightarrow \alpha B\ or\ A \rightarrow \alpha B\beta \ where\ \epsilon \in FIRST(\beta)\Rightarrow FOLLOW(A)\subseteq FOLLOW(B)\)
Predictive Parsing Table
To build a parsing table \(M[A,a]\), for each \(A\rightarrow \alpha\)
- \(\forall a \in FIRST(\alpha):\ M[A,a] = A \rightarrow \alpha\)
- \(\epsilon \in FIRST(\alpha) \Rightarrow \forall b \in FOLLOW(A):\ M[A,b]=A \rightarrow \alpha\)
LL(1) Grammar: Formal Definition
A grammar is LL(1) if and only if any \(A \rightarrow \alpha\ |\ \beta\) satisfies:
- For no terminal \(\alpha\) do both \(\alpha\) and \(\beta\) derive strings starting with \(a\) (by left factoring)
- At most one of \(\alpha\) and \(\beta\) derive the empty string
- if $^* $, \(\alpha\) doesn't derive strings starting with terminals in FOLLOW(\(\alpha\))
Bottom-Up Parsing
Constructing a parse tree in post-order.
- Keep shifting until we see the right-hand side of a rule.
- Keep reducing as long as the tail of our shifted sequence matches the right-hand side of a rule. Then go back to shifting.
LR(0)
We don't need to make decisions during parsing.
- Left-to-right scanning
- Right-most derivation
- Zero symbols of lookahead
Ch6-1
Intermediate Representation
Three Address Code
- Provide a standard reputation
- At most one operator on the right side of each instruction
- At most three addresses/variables in an instruction
Generation of Three-Address Code
Syntax-Directed Definition (SDD)
SDD = Context-Free Grammar + Attributes + Rules
Ch6-2
SSA and Extensions
Static Single-Assighment
Every variable has only one definition.
Direct def-use chains
Using \(\phi\) to merge definitions from multi paths.
1
2
3
4
5
6
7
8if(flag) x = -1;
else x = 1;
y = x * a;
=>
if(flag) x1 = -1;
else x2 = 1;
x3 = \phi(x1, x2);
y = x3 * a;
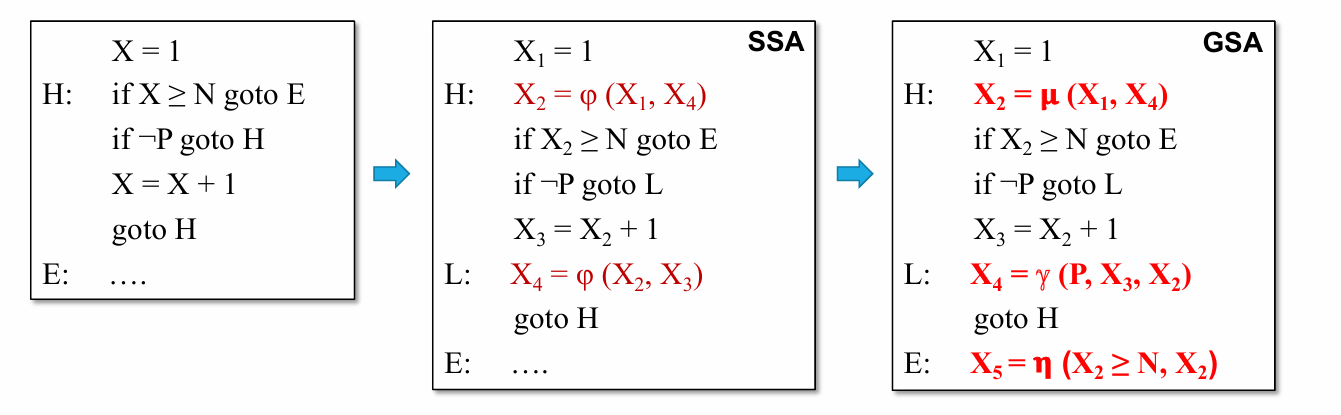
Gated SSA (GSA)
Every variable has only one definition.
Use recursive \(\gamma\) to merge definitions from multi-paths.
Direct def-use chains + conditional def-use chains
1
2
3
4
5
6if(flag) x = -1; else x = 1;
y = x * a;
=>
if(flag) x1 = -1; else x2 = 1;
x3 = \gamma(flag, x1, x2);
y = x3 * a;use \(\mu\) and \(\eta\) for loop variables.
SSA Complexity
Space & Time: Almost linear
LLVM IR
Translation into SSA
Basic Block
A sequence of consecutive instructions.
The first instruction of each block is a leader.
Loop
Dominance & Post-Dominance
- A dom B
- if all paths from Entry to B goes through A
- A post-dom B
- if all paths from B to Exit goes through A
- Strict (post-)dominance - A (post-)dom B but A \(\neq\) B
- immediate dominance - A strict-dom B, but there's no C, such that A strict-dom C, C strict-dom B
Dominator Tree
Almost linear time to build.
- Node: Block
- Edge: Immediate dom relation
(Nearest) common dominator
- LCA - lowest common ancestor
Dominance vs. Ctrl Dependence
Block B is control dependent on Block A
if and only if
- the execution result of A determines if B will be executed.
<=>
- A has multiple successors
- Not all successors can reach B
<=>
- B post-dominates a successor of A
- B does not post-dominates all successors of A
Dominance Frontier
DF(A) = {...}
- The immediate successors of the blocks dominated by A
- Not strictly dominated by A (A itself)
Iterated Dominance Frontier
\(DF(Bset) = \cup_{B\in Bset}DF(B)\)
Iterated DF of Bset:
- DF1 = DF(Bset); Bset = Bset ∪ DF1
- DF2 = DF(Bset); Bset = Bset ∪ DF2
- ……
- until fixed point!
IDF vs. SSA
Ch8-1
Targret Code Generation
- Memory (Heap/Stack/...). Each byte has an address.
- n Registers: R0, R1, ..., Rn-1. Each for bytes.
- Load/Store/Calculation/Jump/...(Like x86 assembly)
In-Block Optimization
Peephole Optimization
Ch8-2
The Lost Copy Problem
The Swap Problem
Ch 8-3
Register Allocation
Pysical machines have limited number of registers.
Register allocation: \(\infty\) virtual registers \(\rightarrow\) \(k\) physical registers
Local Register Allocation
Requirement:
- Produce correct code using \(k\) or fewer registers
- Minimize loads, stores, and space to hold spilled values
- Efficient register allocation (\(O(n)\) or \(O(n\log{n})\))
Spilling:
- saves a value from a register to memory
- the register is then free for other values
- we can load the spilled value from memory to register when necessary
MAXLIVE: the maximum of values live at each instruction
- MAXLIVE ≤ k ---Allocation is trivial
- MAXLIVE > k--- Values must be spilled to the memory
Global Register Allocation
Global allocation often uses the graph-coloring paradigm
- Build a conflict/interference graph
- Find a k-coloring for the graph, or change the code to a nearby problem that it can color
- NP-complete under nearly all assumptions, so heuristics are needed
K-Coloring
- Vertex Coloring: assign a color to each vertex such that no edge connects vertices with the same color.
- K-Coloring: a coloring using at most k colors.
K-Coloring for Register Allocation
- Map graph vertices onto virtual registers
- Map colors onto physical registers
From live ranges construct a conflict graph, color the graph so that no two naighbors have the same color.
If graph needs more than \(k\) colors -> Spilling.
A vertex such that its degree < k is always k-colorable.
Chaitin's Algorithm
Remove vertices whose degree < k, and push them to a stack until the graph becomes empty.
When the algorithm reaches a state where every vertex has a degree \(\geq\) k:
- Choose a vertex immediately to spill
- put the vertex into a spill list
- remove the vertex from the graph
- continue moving vertices < k degree from the graph to the stack
- If the spill list is not empty, insert spill code, rebuild conflict graph, and retry allocation.
Chaitin-Briggs Algorithm
Degree of a vertex is a loose upper bound on colorability.
A vertex such that its degree < k is always k-colorable.
A vertex such that its degree \(\geq\) k may also be k-colorable.
- Choose a vertex immediately to spill
- push the vertex (to spill) to the stack
- we may have a color availble when it is popped
Compared to Chaitin's Algorithm, Chaitin-Briggs Algorithm delays the spill operation.
Spill Candidates
Alternative Spilling
Spliting Live Ranges, Coalescing Virtual Registers(Does'nt always work), etc.
Ch9-1
Data Flow Analysis
The Worklist Algorithm
For each basic block B, initialize IN[B] an OUT[B].
worklist = set of all basic blocks.
while(!worklist.empty()):
B = worklist.pop;
IN[B] = \(\and\)\(_{P\in pred(B)}\)OUT[P];
OUT[B] = \(f_B\)(IN[B]);
if OUT[B] changed:
worklist.push(all B's successors)
Reaching Definitions
A definition d may reach a program point, if there is a path from d to the program point such that d is not killed along the path.
OUT[B] = \(f_B\)(IN[B]) = $gen_B $ (IN[B] - \(kill_B\))
IN[B] = \(\and_{P\in preds(B)}\)OUT[P] = \(\cup_{p \in preds(B)}\)OUT[P]
Available Expressions
An expression x + y is available at a point p if:
- every path from the entry node to p evaluates x + y, and
- after the last such evaluation prior to reaching p, there are no subsequent assignments to x or y.
OUT[B] = \(e\_gen_B \cup (IN[B]-e\_kill_B)\)
IN[B] = \(\cap_{P\ a\ predecessor\ of\ B}\)OUT[P]
Live Variable Analysis
A dead value
After a variable is revised, its previous value (in the register) is dead
A live value
- A variable is not be re-defined
- After loading to a register, the value in the register is valid
Backward data flow analysis
IN[B] = \(uses_B \cup (OUT[B]-def_B)\)
OUT[B] = \(\cup_{S\ a\ successor\ of\ B}\) IN[S]
Partical Redundancy
Sources of Redundancy
- Common expression
- Loop invariant motion
- Partical Redundancy
The Lazy Code Motion Problem
- All redundant computations of expressions that can be eliminated without code duplication are eliminated.
- The optimized program does not perform any computation that is not in the original program execution.
- Expressions are computed at the latest possible time.
Step 1: Anticipated Expressions (Backwards)
Step 2: Available Expressions (Forwards)
Step 3: Postponable Expressions (Forwards)
Step 4: Used Expressions (Backwards)
Constant Propagation
Feature 1: It has an unbounded set of possible data-flow values
Feature 2: It is not distributive
x = y + z
m(y) = Constant, m(z) = Constant => m(x) = Constant
either of m(y) and m(z) is UNDEF => m(x) = UNDEF
otherwise => m(x) = NAC
m(x) \(\and\) m(x')
UNDEF \(\and\) Constant = Constant
NAC \(\and\) Constant = NAC
Constant \(\and\) Constant = Constant
Constant \(\and\) Constant' = NAC